เกริ่นนำ
ปกติเวลาเราทำงานกับ tabular data แล้วเนี่ยเราก็จะมักเก็บไฟล์เป็นแบบ csv กันใช่มั้ยครับ เพราะมันสะดวกดี แต่จริง ๆ แล้วเจ้า csv มันก็มีข้อเสียของมันคือค่อนข้างช้าครับ วันนี้ผมเลยทำการทดสอบสั้น ๆ เพื่อเทียบประสิทธิภาพของ csv เทียบกับไฟล์ฟอร์แมตยอดฮิตอีก 3 ตัวนั่นก็คือ parquet, pickle และ feather ครับ เราลองมาดูกันว่าตัวไหนจะมีประสิทธิภาพดีที่สุด
เริ่มจากโหลด library ต่าง ๆ
import pandas as pd
import seaborn as sns
import os
from timeit import default_timer as timerลองโหลด data ของเรามา ขนาดประมาณ 120 Mb ครับ
measure_list = []
df = pd.read_csv('dummy_data.csv')เวลาที่ใช้ในการอ่านเขียนไฟล์
ต่อไปจับเวลาเขียนไฟล์แต่ละประเภท แล้วเก็บผลไว้ใน list แต่เนื่องจากการอ่านเขียนแต่ละครั้งจะได้ผลต่างกันเล็กน้อย ผมจึงลองทำทั้งหมด 10 ครั้งแล้วหาค่าเลี่ยครับ
for i in range(10):
start = timer()
df.to_csv('dummy_data.csv', index=False)
measure_list.append({'type':'csv', 'operation':'write', 'time': timer()-start})
start = timer()
df.to_parquet('dummy_data.parquet')
measure_list.append({'type':'parquet', 'operation':'write', 'time': timer()-start})
start = timer()
df.to_pickle('dummy_data.pkl')
measure_list.append({'type':'pickle', 'operation':'write', 'time': timer()-start})
start = timer()
df.to_feather('dummy_data.ftr')
measure_list.append({'type':'feather', 'operation':'write', 'time': timer()-start})ต่อไปลองจับเวลาอ่านไฟล์แต่ละประเภทครับ
for i in range(10):
start = timer()
_ = pd.read_csv('dummy_data.csv')
measure_list.append({'type':'csv', 'operation':'read', 'time': timer()-start})
start = timer()
_ = pd.read_parquet('dummy_data.parquet')
measure_list.append({'type':'parquet', 'operation':'read', 'time': timer()-start})
start = timer()
_ = pd.read_pickle('dummy_data.pkl')
measure_list.append({'type':'pickle', 'operation':'read', 'time': timer()-start})
start = timer()
_ = pd.read_feather('dummy_data.ftr')
measure_list.append({'type':'feather', 'operation':'read', 'time': timer()-start})เอาผลที่ได้มาทำเป็น dataframe แล้ว plot กราฟดู
result_df = pd.DataFrame(measure_list)sns.set(rc={'figure.figsize':(7, 5)}, font='Arial', font_scale=1.3)
ax = sns.barplot(x='type', y='time', hue='operation', data=result_df)
for p in ax.patches:
height = p.get_height()
ax.text(p.get_x()+p.get_width()/2., height + 0.7, '{:1.2f}'.format(height), ha="center") 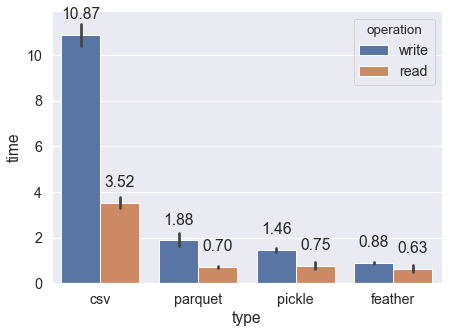
เราจะเห็นได้ว่า csv ช้าที่สุดทั้งอ่านและเขียนครับ (ช้าแบบบ้าบอมาก) ส่วน feather นั้นเร็วที่สุดในบรรดา 4 ตัวครับผม panquet กับ pickle นั้นเร็วกว่า csv แต่ช้ากว่า feather ครับ
ขนาดของไฟล์ที่เก็บบนเครื่อง
print(f'csv file size: {os.path.getsize("dummy_data.csv")>>20} MB')
print(f'feather file size: {os.path.getsize("dummy_data.ftr")>>20} MB')
print(f'parquet file size: {os.path.getsize("dummy_data.parquet")>>20} MB')
print(f'pickle file size: {os.path.getsize("dummy_data.pkl")>>20} MB')csv file size: 119 MB
feather file size: 188 MB
parquet file size: 19 MB
pickle file size: 157 MB
เราจะเห็นได้ว่า ถึงแม้ feather จะมี performance ดีที่สุด แต่ว่าขนาดของไฟล์ก็จะมีขนาดใหญ่ที่สุดครับ ถ้าอยากประหยัดพื้นที่เก็บไฟล์ด้วย แนะนำให้ใช้ parquet ดีกว่าครับ